
By : Tri A. Budono
Date : 13 August 2020
Reading time: 1841 words or 8 minutes
Data Structures & Algorithms (DSA) is an important course. DSA is a fundamental core computer science concepts. You will need to use what you learned in this course later in your study and later in your profession. If you apply for any job involving software development, you will be asked about DSA in job interviews. If you want to become a software engineer, but don’t know where to start, DSA is your assured bet to go. Once you get the essence of these pillars of programming, you will start seeing them everywhere. The more algorithms and data structures you learn, the more they will serve as jet fuel for your career as a software engineer.
Even though DSA requires some mathematical analysis, this course emphasize practical concerns. To get a full sense of DSA, you need to get your hand dirty with coding and programming. The best way to learn is by doing. The course gives you the tools required to analyze a problem and decide which algorithms and data structures to apply. And the emphasis on the practical concerns is substantiated in the projects that will help you become confident with a range of data structures and algorithms and able to apply them in a realistic way.
While working on the DSA projects and before start implementing the solution, an analysis is required to determine what data structures to use and why it was chosen. This analysis is crucial to the overall quality of the delivered project, notably the performance and scalability of the program. Apparently though, throughout years of observing the student projects, there is some pattern of mistakes that recurring:
- Students chose the data structures out of familiarity and convenience, not for performance
- Students used general reasons to justify the selection of data structures, not for the characteristics of the problem.
It’s not uncommon in the project report, the students wrote:
“…In our program, our main data structure would be the linear data structure type. The reason we chose this structure is due to its simplicity and convenience to operate. It is also more easily understandable to us.”
“…So after long consideration, we settled with a linear array data structure because of a few reasons: First, we already familiarize our self working with arrays from the first semester. Secondly, a lot of resources were put into thoughts in the process of implementing the algorithm that we use.”
Similarly, it’s also very common in the project report, the students stated:
“…Upon further inspection of these two data structures, it was decided that using a list would be better than using an array, this is due to the resizing capabilities of a list. For array, size is limited to a number that is initially defined, therefore it would be hard to store a huge amount of data, on the other hand, lists are able to resize themselves depending on its content. It gives freedom for users to update data and store them without wasting space or is limited by space.”
“…My first opinion would be I think having a fixed size for player Inventory is better than having a dynamic and flexible size because in Array the memory is already assigned during compile time, also in most RPG. Weapon, armours and items are already predefined and here why I don’t pick the other candidate.”
One may argue that with the availability of increasingly speedy computers and cheap storages, the need of fast algorithms and responsive data structures is becoming less important. However, the new problems keep arising and they require increasingly larger data to work with. The term Big Data signifies this trend: the more powerful the computer is, the more complex the problems will be, and the larger datasets it will need to tackle. Therefore, an ability to analyze the computational requirements in accordance with the problem characteristics to determine the right data structures is even more critical as the way we store data dictates how much data an algorithm has to move. Choosing the right data structure for your program can spell the difference between bearing a heavy load or collapsing under it.
So, when selecting a data structure to solve a problem, you should follow these steps.
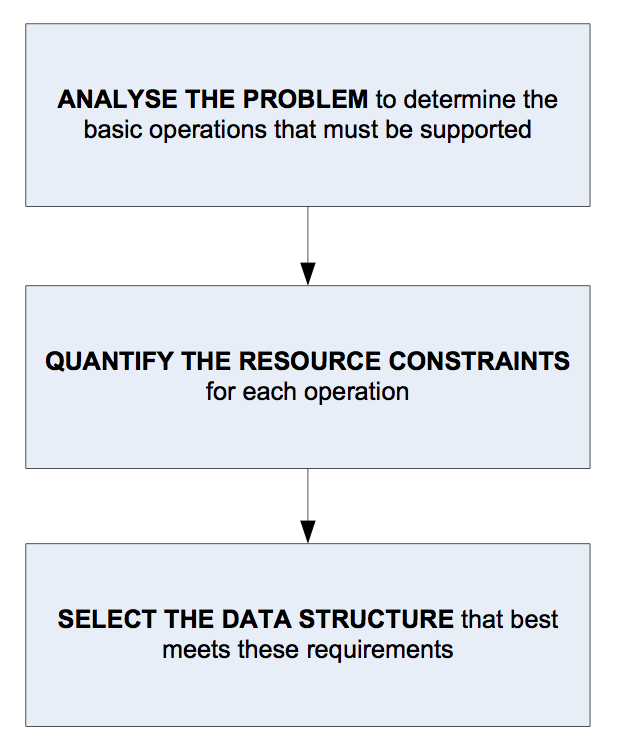
Figure 1. The general steps of data structure analysis
More specifically, the general steps above can be more easily followed by answering the following guiding questions:
Box 1. The detailed guiding questions to determine the appropriate data structures for the problem (adapted from OpenDSA)
|
1 What is the resource constraints on certain key operations, that is required by the algorithm such as search, inserting data records, and deleting data records? 1.1 How the algorithm makes use of the basic operations of data structures in some relative proportion? 1.1.1 What operation is the most frequent? 1.1.2 Which operation is required to be efficient? 1.1.3 Which operation is fine even though is it not efficient?
2 What is the relative importance of these operations? 2.1 Are all data items inserted into the data structure at the beginning, or are insertions interspersed with other operations? 2.1.1 Static applications (where the data are loaded at the beginning and never change) typically get by with simpler data structures to get an efficient implementation, while 2.1.2 Dynamic applications [requiring data update, data update can affect space] often require something more complicated. 2.2 Can data items be deleted? 2.2.1 If so, this will probably make the implementation more complicated. 2.3 Are all data items processed in some well-defined order, or is search for specific data items allowed? 2.3.1 “Random access” search generally requires more complex data structures.
|
Let show how these steps are applied by examining a simple model of the bank.
“A bank must support many types of transactions with its customers, where customers wish to open accounts, close accounts, and add money or withdraw money from accounts.”
PROBLEM ANALYSIS
| The typical customer opens and closes accounts far less often than he or she accesses the account. Customers are willing to wait many minutes while accounts are created or deleted but are typically not willing to wait more than a brief time for individual account transactions such as a deposit or withdrawal. These observations can be considered as informal specifications for the time constraints on the problem.
It is common practice for banks to provide two tiers of service: 1 Human tellers or automated teller machines (ATMs) support customer access to account balances and updates such as deposits and withdrawals. Teller and ATM transactions are expected to take little time. 2 Special service representatives are typically provided (during restricted hours) to handle opening and closing accounts. Opening or closing an account can take much longer (perhaps up to an hour from the customer’s perspective).
|
RESOURCE CONSTRAINT QUANTIFICATION
| From a database perspective, we see that ATM transactions do not modify the database significantly.
1 For simplicity, assume that if money is added or removed, this transaction simply changes the value stored in an account record. 2 Adding a new account to the database is allowed to take several minutes. 3 Deleting an account need have no time constraint because from the customer’s point of view all that matters is that all the money be returned (equivalent to a withdrawal). 4 From the bank’s point of view, the account record might be removed from the database system after business hours, or at the end of the monthly account cycle.
|
We can put the above analysis into a compact table below:
Table 1. Resource (time and space) constraints identification
| Problem-level | Data Structure -level | |||
| User Req Level | Resource (time) Constraint | Key operation | Resource Constraint | |
| Time | Space | |||
| Open Account | Customers are willing to wait many minutes while accounts are created | insert | slow | no issue |
| Close Account | Customers are willing to wait many minutes while accounts are closed | delete | slow | no issue |
| Deposit Money | Customers are typically not willing to wait for more than a brief time for deposit or withdrawal. Transactions are expected to take little time. | update | fast | no issue |
| Withdraw money | Customers are typically not willing to wait for more than a brief time for deposit or withdrawal. Transactions are expected to take little time. | update | fast | no issue |
| Transfer Money | Customers are typically not willing to wait for more than a brief time for deposit or withdrawal. Transactions are expected to take little time. | update | fast | no issue |
| Check Balance | Customers are typically not willing to wait for more than a brief time for deposit or withdrawal. Transactions are expected to take little time. | exact query | fast | no issue |
DATA STRUCTURE SELECTION
| When considering the choice of data structure to use in the database system that manages customer accounts, we see that a data structure that has little concern for the cost of deletion but is highly efficient for search and moderately efficient for insertion, should meet the resource constraints imposed by this problem. Records are accessible by unique account number (sometimes called an exact-match query).
One data structure that meets these requirements is the hash table: · Hash tables allow for extremely fast exact-match search. · A record can be modified quickly when the modification does not affect its space requirements. Hash tables also support efficient insertion of new records. · While deletions can also be supported efficiently, too many deletions lead to some degradation in performance for the remaining operations. · However, the hash table can be reorganized periodically to restore the system to peak efficiency. Such reorganization can occur offline so as not to affect ATM transactions.
|
As the example above shows, selecting an appropriate data structure for the problem can be done in a systematic and methodical step. Many times, even professional programmers forget this step. Yet, only by first analyzing the problem to determine the performance goals that must be achieved can there be any hope of selecting the right data structure for the job. Poor program designers ignore this analysis step and apply a data structure that they are familiar with but which is inappropriate to the problem. The result is typically a slow program. Conversely, there is no sense in adopting a complex data structure to improve a program that can meet its performance goals when implemented using a simpler design.
So, even for the task as trivial as student projects, the danger of choosing data structures based on familiarity or convenience is apparent. It can make or break our application programs! Never forget this analysis step anymore!
Bibliography
- Student Projects in COMP6571 Data Structure and Algorithm courses at Binus University International, Odd semesters 2019 and 2020
- OpenDSA project at Virginia Technology University, available on https://opendsa-server.cs.vt.edu/
- Idreos, et al., “The Periodic Table of Data Structures,” Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, vol. 41, no. 3, pp. 64-75, 2018.
- Idreos, et al., “Learning Data Structure Alchemy,” Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, vol. 42, no. 2, pp. 46-57, 2019.